What is a Robots.txt file?
Robots.txt is a standard file that the websites use to instruct the spiders or web crawlers such as Googlebot when they are visiting your websites or marketplaces.
So basically, you are telling Google and Bing or MSN or all other basic search engines what they can and can not see on your websites. More importantly, what they are allowed to see and where they are allowed to go on your websites or marketplaces.
Why do I need a robot.txt file?
If you are not using a robot.txt file then a lot of things that can go wrong with your marketplace or a website like –
- Prone to errors.
- Your websites will not be optimized in terms of crawlability.
- Sensitive data can be crawled by the bots and indexed in the search results and can get visible to the searchers.
- It helps to prevent duplicate content issues, which is important to SEO success.
- It helps to hide the technical details of your site i.e error logs, SVN files, unwanted pages, cart page, login page, and the checkout page, etc. Since these are prevented, you are left with clean URLs to be indexed by the search engines.
- You can use the non-standard crawl directives to slow down the search engines like the crawl delay directive that can slow down the crawl hungry search engines.
Every site has an allotment of the number of pages the search crawler will crawl, usually called the crawl budget. Blocking the sections of your site from the search crawlers allows you to use this allotment for the other sections of your website.
How to create a robots.txt file?
First, you need to check whether your website is having a robots.txt file, you can check it by going to your website URL and adding the text robots.txt at the end – www.example.com/robots.txt. If you are having this file then you will see it or else if it’s not then you can create one easily.
You can create a robots.txt file by using a whole bunch of text editors that are available in the market. Open your notepad to start writing the robots.txt file.
After you have created this file with what you want to allow and disallow, you have to upload it to your website’s root folder.
A screenshot has been shared below to let you know how the Opencart robots.txt file appears visually.
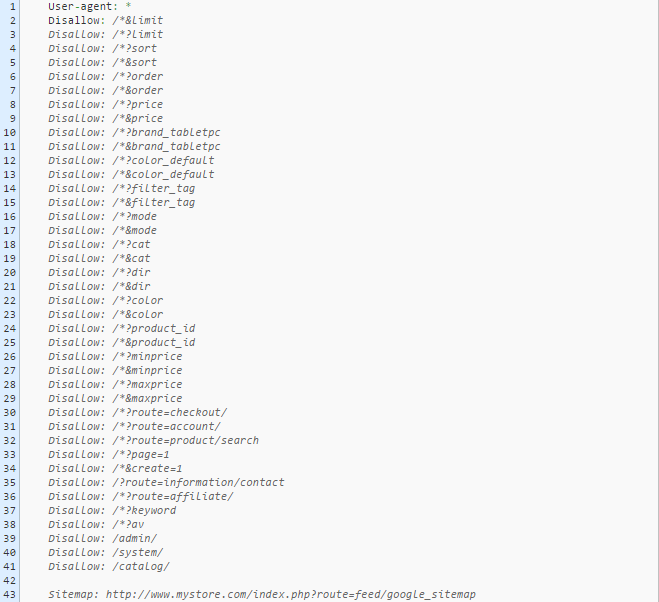
- Start writing the robots.txt file with declaring something and identifying what web crawler is coming to the website.
For example –
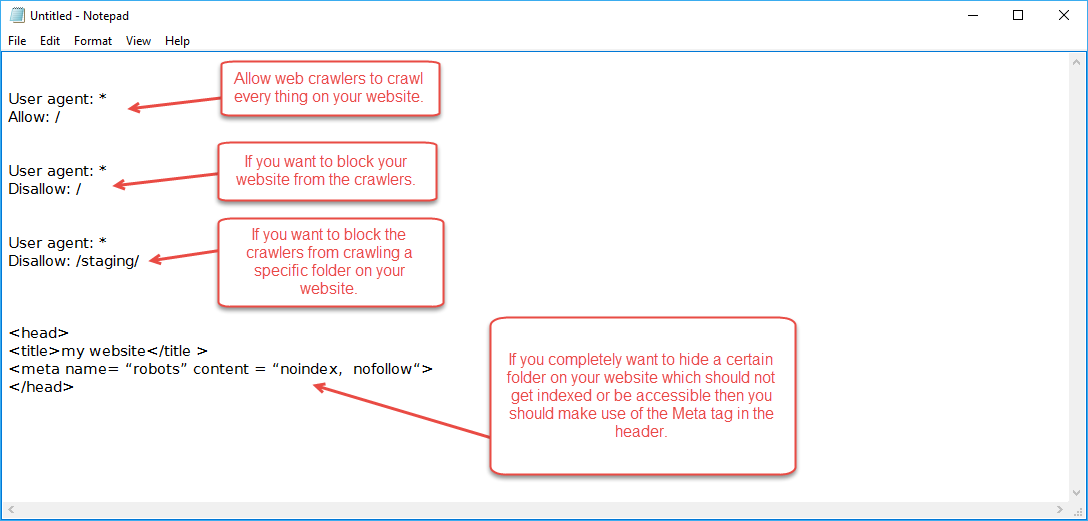
User-agent : *
Allow: /
This says that any web crawlers coming to the website can crawl everything. If you want to block your website from all crawlers then just replace Allow: / by Disallow: / in the above example.
Certain people specify specific user agents like the Googlebot or other random ones that people typically do really focus on and will start the robots.txt with User-agent: Googlebot and then they will disallow certain parts of their websites.
- Say your website is having a folder staging and it has some test data and other duplicate content that you do not want to show up in the search results. Just write –
User agent : *
Disallow: /staging/
This is just a suggestion to any of the crawlers coming to the site not to crawl this folder. But if any malicious crawler comes it can ignore the robots.txt file and hence is not a good security mechanism.
There are advantages and disadvantages to this. This is not a way to hide your sensitive data as it’s just an instruction to crawl or not.
- If specifically, you want to hide your website data you can make use of the Meta tag. Go to the actual page, that is to be hidden and insert the meta tag in the head of the webpage. It will be something like –
<html>
<head>
<title>My Website</title >
<meta name= “robots” content = “noindex, nofollow”
</head>
</html>
This code will instruct “Do not index this content“, hence the crawlers will not be able to index this website page and provides a good mechanism in hiding the sensitive data on your website or marketplaces from the crawlers.
Thus making the best or most effective use of the robots.txt file you will be able to make a set of rules for the search crawlers. The rules will guide them on what they are allowed to see and where they are allowed to go on your websites. For more information click here robots.txt specifications.
Hope this was somewhat helpful. Stay put! for the next article that’s on Search Engine Friendly URLs.


Be the first to comment.